
Introduction
Transitioning on-prem operations to a cloud-centric approach is a critical step for organizations aiming to enhance scalability, reduce maintenance costs, and accelerate innovation. Adopting a Cloud Center of Excellence (CCoE), DevOps, and Site Reliability Engineering (SRE) practices can significantly contribute to successful digital transformation. This article provides a comprehensive guide to understanding these concepts and outlines the steps involved in the transition process.
Background
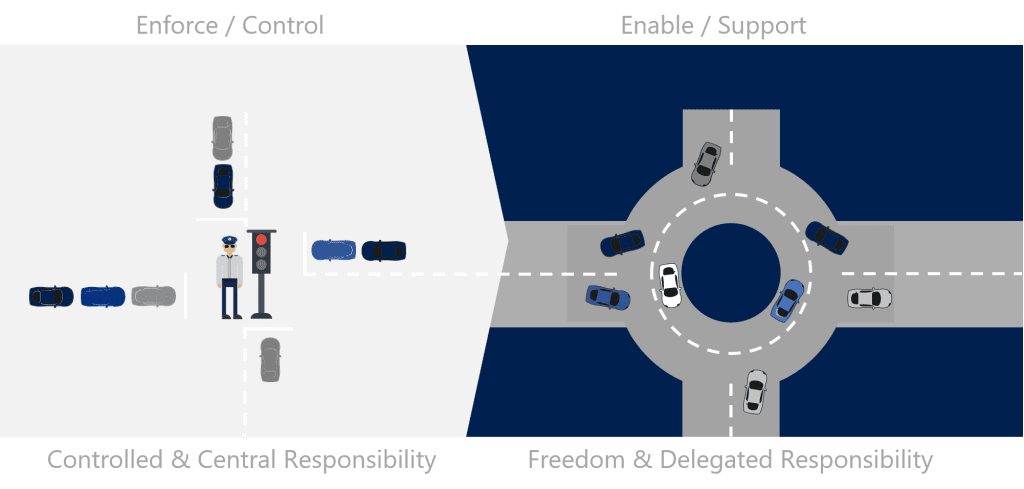
Traditionally, many companies have handled development and operations separately, leading to challenges such as limited scalability, high maintenance costs, and slow innovation cycles. The separation of development (Dev) and operations (Ops) often results in silos, where each team works independently, causing delays and inefficiencies. Development teams focus on creating new features and functionalities, while operations teams are responsible for maintaining the stability and performance of the systems. This division can lead to a lack of collaboration and communication between the teams, resulting in slower response times to issues and a longer time-to-market for new features.
With the advent of cloud computing, there is a need to adopt a more integrated approach that aligns with modern practices and technologies. Cloud platforms offer scalable and flexible infrastructure, enabling organizations to quickly adapt to changing business needs. However, to fully leverage the benefits of the cloud, organizations must transition from traditional on-prem operations to a cloud-centric model that promotes collaboration, agility, and continuous improvement.
Cloud Center of Excellence (CCoE)
Role and Responsibilities
The Cloud Center of Excellence (CCoE) is a cross-functional team that provides governance, best practices, and support for cloud adoption. It plays a crucial role in driving the organization’s cloud strategy and ensuring that cloud initiatives align with business goals. The CCoE acts as a central hub for cloud expertise, offering guidance and resources to various teams within the organization. By establishing a CCoE, organizations can ensure a consistent and standardized approach to cloud adoption, reducing the risk of misconfigurations and security vulnerabilities.
Structure of the CCoE
The CCoE typically consists of three main teams, each with distinct roles and responsibilities:
Solution Architecture Team
The Solution Architecture Team is responsible for providing guidance, solution patterns, and training to the DevOps teams. They help identify workloads that are suitable for migration to the cloud and assist in designing cloud-native architectures that meet the organization’s requirements. The team also plays a key role in onboarding and coaching DevOps teams, ensuring that they follow best practices and adhere to architectural standards. By offering hands-on support and training, the Solution Architecture Team helps DevOps teams build the skills and knowledge needed to successfully adopt cloud technologies.
Product Team
The Product Team focuses on designing, building, and publishing preconfigured Azure ‘Products’ that can be reused by various DevOps teams. These products are essentially deployment packages that include infrastructure as code (IaC) templates, configuration settings, and best practices for specific use cases. By providing a catalog of reusable components, the Product Team ensures that DevOps teams can quickly and easily deploy cloud resources that are secure, compliant, and optimized for performance. This approach not only accelerates the deployment process but also promotes consistency and standardization across the organization.
Platform Team
The Platform Team is responsible for building and driving the CCoE vision, strategy, and roadmap. They define and evangelize DevOps and cloud-native principles, ensuring that the organization adopts a culture of continuous improvement and innovation. The Platform Team also manages change and adoption, helping teams transition from traditional on-prem operations to a cloud-centric model. By providing the necessary tools, frameworks, and support, the Platform Team enables DevOps teams to focus on delivering value to the business while maintaining a stable and secure cloud environment.

DevOps
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to shorten the development lifecycle and deliver high-quality software continuously. The core philosophy of DevOps is “you build it, you run it, you own it,” which emphasizes the responsibility of DevOps teams for the end-to-end lifecycle of their applications. This approach fosters a culture of collaboration and accountability, where teams work together to achieve common goals.
Key Benefits of Adopting DevOps
- Faster Innovation and Time-to-Market: By automating repetitive tasks and streamlining processes, DevOps enables teams to deliver new features and updates more quickly. Continuous integration and continuous delivery (CI/CD) pipelines allow for faster feedback loops and quicker resolution of issues, reducing the time it takes to bring new products to market.
- Improved Reliability and Stability: DevOps practices, such as automated testing, monitoring, and incident response, help ensure that applications are reliable and stable. By identifying and addressing issues early in the development process, teams can prevent problems from escalating and impacting end-users.
- Better Alignment with Business Goals and Customer Needs: DevOps promotes a customer-centric approach, where teams continuously gather feedback and iterate on their products to meet the evolving needs of the business and its customers. This alignment helps organizations stay competitive and responsive to market demands.
Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) is a discipline that applies software engineering principles to IT operations. It focuses on improving the reliability, scalability, and efficiency of applications by automating operations tasks and implementing best practices. SRE practices can support both large and small projects, ensuring that systems are resilient and performant.
Key Principles of SRE
- Automation: SRE emphasizes the use of automation to reduce manual intervention and minimize human error. By automating repetitive tasks, such as deployments, monitoring, and incident response, SRE teams can improve the efficiency and reliability of their systems.
- Reliability: SRE teams focus on ensuring that applications meet defined reliability targets, such as uptime and performance. They use techniques like error budgets, which quantify the acceptable level of failure, to balance reliability with the need for rapid innovation.
- Scalability: SRE practices help organizations design systems that can scale efficiently to handle increased load and demand. This includes implementing strategies for capacity planning, load balancing, and performance optimization.
- Incident Management: SRE teams are responsible for managing incidents and ensuring that issues are resolved quickly and effectively. They use tools and processes to detect, diagnose, and remediate problems, minimizing the impact on end-users.
Integration with CCoE and DevOps
SRE practices can be integrated into the CCoE and DevOps framework to enhance the overall reliability and scalability of applications. By incorporating SRE principles, organizations can ensure that their cloud infrastructure and applications are designed and operated with a focus on reliability and performance. SRE teams can work alongside DevOps teams to implement best practices for monitoring, incident response, and capacity planning, ensuring that applications meet reliability targets.
Transition Process
Transitioning from on-prem operations to a cloud-centric approach involves several key steps:
Structured Training and Onboarding
Implementing a structured training program is essential to help team members acquire the necessary skills for working with Azure. This can include formal training courses, hands-on labs, and certifications. Encouraging knowledge sharing and collaboration within the team can also build a strong internal support network. Training should cover various aspects of cloud adoption, including cloud architecture, security, compliance, and DevOps practices. By providing comprehensive training, organizations can ensure that their teams are well-prepared to navigate the complexities of cloud adoption.
Clustering Smaller Projects
For smaller projects, clustering them into specific groups can be effective. This approach allows for shared resources and expertise, making it easier to manage and support multiple projects simultaneously. By grouping related projects together, organizations can leverage common tools, processes, and best practices, reducing duplication of effort and improving efficiency. Clustering also enables teams to share knowledge and collaborate more effectively, fostering a culture of continuous improvement.
Expanding the Service Catalog
Establishing best practices for commonly used services and gradually expanding the service catalog allows the team to build expertise incrementally and adapt to new services as they are adopted. The service catalog should include preconfigured templates, guidelines, and best practices for deploying and managing cloud resources. By providing a comprehensive catalog of services, organizations can ensure that their teams have access to the tools and resources they need to succeed in the cloud.
Guidance and Support
The Solution Architecture Team within the CCoE provides guidance and support to the business unit DevOps teams, ensuring they follow best practices and architectural standards. This includes offering hands-on assistance with designing and implementing cloud solutions, conducting architectural reviews, and providing ongoing support and mentorship. By acting as a trusted advisor, the Solution Architecture Team helps DevOps teams navigate the complexities of cloud adoption and ensures that their solutions are aligned with organizational goals.
Motivating People During the Transition
Motivating team members to embrace the transition is crucial for its success. The Prosci ADKAR model is a useful framework for managing change and can be applied to help team members understand the need for change, build desire, acquire knowledge, develop ability, and reinforce the change. Here’s how to apply the ADKAR model:
Awareness
Communicate the reasons for the transition and the benefits it will bring to the organization and individual team members. This includes highlighting the advantages of cloud adoption, such as increased scalability, reduced costs, and faster innovation. By clearly articulating the vision and goals of the transition, organizations can help team members understand the importance of embracing change.
Desire
Address any concerns and highlight the opportunities for personal and professional growth that the transition offers. This can include showcasing success stories, providing incentives, and creating a supportive environment that encourages experimentation and learning. By fostering a positive attitude towards change, organizations can build a strong foundation for successful cloud adoption.
Knowledge
Provide training and resources to help team members acquire the necessary skills and knowledge for working with Azure and adopting DevOps practices. This includes offering access to online courses, workshops, and certification programs, as well as creating opportunities for hands-on learning and experimentation. By investing in the development of their teams, organizations can ensure that they have the expertise needed to succeed in the cloud.
Ability
Offer hands-on experience and support to help team members apply their new skills and knowledge in real-world scenarios. This can include providing access to sandbox environments, facilitating peer-to-peer learning, and offering mentorship and coaching. By creating opportunities for practical application, organizations can help team members build confidence and competence in their new roles.
Reinforcement
Recognize and reward progress and achievements to reinforce the desired behaviors and ensure the change is sustained. This can include celebrating milestones, providing feedback and recognition, and creating a culture of continuous improvement. By reinforcing positive behaviors, organizations can ensure that the transition to the cloud is successful and sustainable.
Handling New Technologies
Introducing new technologies that haven’t been approved yet can be managed through a collaborative and efficient process:
Request and Evaluation
DevOps teams can submit a request for the new technology to the Solution Architecture Team, which evaluates the request based on factors such as alignment with organizational goals, security, compliance, and potential benefits. This evaluation process ensures that new technologies are assessed thoroughly before being adopted, minimizing risks and ensuring that they align with the organization’s strategic objectives.
Fast-Track Approval
Establishing a fast-track approval process for new technologies that are critical for business needs involves a quick assessment and, if necessary, a temporary approval while a more thorough review is conducted. This approach allows teams to quickly adopt new technologies that are essential for their projects while ensuring that they undergo a comprehensive evaluation in the long term.
Continuous Improvement
Encouraging a culture of continuous improvement where feedback from DevOps teams is regularly collected and used to update the product catalog ensures that the catalog remains relevant and up-to-date with the latest technologies and best practices. By fostering an environment of continuous learning and adaptation, organizations can stay ahead of technological advancements and maintain a competitive edge.
Cost Management and FinOps Principles
Effective cost management is essential for cloud adoption. FinOps (Financial Operations) brings financial accountability to the variable spend model of cloud, enabling teams to manage their cloud costs effectively. Here are the key points:
DevOps Teams (or Solution Teams)
These teams are responsible for the end-to-end lifecycle of their applications, including managing their budget and costs. They need to be aware of their spending and optimize costs while delivering value. By integrating cost management practices into their workflows, DevOps teams can ensure that they are making informed decisions that balance performance and cost efficiency.
Product Teams
In the context of the CCoE, the Product Team is responsible for creating and maintaining certified products and the product catalog. This is more of a central team that provides reusable components to the solution teams. By offering preconfigured products that adhere to best practices for cost optimization, the Product Team helps DevOps teams deploy cost-effective solutions that meet their needs.
Platform Teams
The Platform Team plays a crucial role in managing central components such as VPN Gateways, central Firewalls, and other shared infrastructure. They are responsible for ensuring that these central components are cost-effective, secure, and scalable. The Platform Team also oversees the implementation of FinOps principles across these shared services, ensuring that costs are monitored, optimized, and aligned with business goals. By managing these central components, the Platform Team enables other teams to focus on their specific applications and services without worrying about the underlying infrastructure.
Naming Clarification
To avoid confusion, the term “Product Team” within the CCoE refers to the central team responsible for managing the product catalog. In contrast, “Solution Teams” or “DevOps Teams” are the teams responsible for individual products or clustered products. This distinction ensures that roles and responsibilities are clearly defined, and each team understands its specific functions within the organization
Evolving IT Operations: From Traditional to Modern Approaches
Traditional IT operations have long relied on established practices and procedures to maintain system stability and performance. These operations typically involve separate teams for development and operations, leading to challenges such as limited scalability, high maintenance costs, and slow innovation cycles. However, with the advent of cloud computing and modern practices, the roles for handling incidents and other responsibilities have evolved. This section will cover both traditional IT operations and the transition to modern practices, including the use of operations manuals, responsibility for incidents, integrated on-call rotation and collaboration, and the RACI matrix for defining roles and responsibilities
With the advent of cloud computing, there is a need to adopt a more integrated approach that aligns with modern practices and technologies. Cloud platforms offer scalable and flexible infrastructure, enabling organizations to quickly adapt to changing business needs. However, to fully leverage the benefits of the cloud, organizations must transition from traditional on-prem operations to a cloud-centric model that promotes collaboration, agility, and continuous improvement.
Operations Manual
Traditional IT teams use operations manuals to provide knowledge on how to solve specific problems. This can include detailed steps for handling incidents, such as an Azure Kubernetes Cluster error. Operations manuals serve as a valuable resource for troubleshooting and maintaining systems, ensuring that teams have access to the information they need to resolve issues efficiently.
Responsibility for Incidents
In a cloud-centric approach, the responsibility for dealing with incidents should be clearly defined. For example:
- DevOps Teams (or Solution Teams): Typically responsible for handling incidents related to their applications, including Azure Kubernetes Cluster errors. They have the necessary context and knowledge to quickly address issues and ensure the stability of their applications.
- Solution Architecture Team: Provides guidance and support but does not directly handle incidents. They offer expertise and advice to help DevOps teams design resilient architectures and implement best practices.
- Platform Team: Manages the underlying infrastructure and ensures it is secure, scalable, and reliable. They handle tasks such as patching, monitoring, and capacity planning for the infrastructure layer.
- Separate Ops Team: Can provide 24/7 support for critical incidents that require specialized expertise or coordination across multiple teams. This team focuses on platform services and ensures that the infrastructure remains operational and performant.
Integrated On-Call Rotation and Collaboration
To address the need for 24/7 support without creating silos, DevOps teams can have an integrated on-call rotation where team members take turns being on-call. This ensures that the person handling the incident has the necessary context and knowledge of the application. Collaboration tools can facilitate communication between DevOps teams and other specialized teams (e.g., AKS engineers) when needed, ensuring that expertise is available without creating silos. By leveraging collaboration tools, teams can share knowledge, coordinate responses, and resolve issues more effectively.
RACI Matrix for Roles and Responsibilities
The RACI matrix is a valuable tool for defining roles and responsibilities. It helps clarify who is Responsible, Accountable, Consulted, and Informed for each task or decision. By using a RACI matrix, organizations can ensure that everyone understands their specific roles and responsibilities, reducing confusion and improving coordination.
RACI Matrix for Handling Incidents
| Task/Responsibility | DevOps Teams (Solution Teams) | Solution Architecture Team | Product Teams | Platform Team |
|---|---|---|---|---|
| Incident Detection | R | C | I | I |
| Incident Response | R | C | I | A |
| Root Cause Analysis | R | C | I | A |
| Implementing Fixes | R | C | I | A |
| Monitoring and Reporting | R | C | I | A |
| Infrastructure Patching | R (for their infrastructure) | C | I | R (for central infrastructure) |
| Capacity Planning | I | C | I | R |
| Security Management | R (for application security) | C | C | R (for central components) |
| Documentation and Knowledge Base | R | C | I | A |
Key:
- R: Responsible – The team that does the work to complete the task.
- A: Accountable – The team that is ultimately answerable for the correct and thorough completion of the task.
- C: Consulted – The team that provides information and expertise necessary to complete the task.
- I: Informed – The team that needs to be kept up-to-date on the progress and completion of the task.
This RACI matrix is an exemplary model to help understand the concept. Most companies might need to adapt this matrix according to their specific needs and organizational structure
Example: Root Cause Analysis
To illustrate the roles and responsibilities in more detail, let’s take the example of root cause analysis:
- DevOps Teams (Solution Teams) are responsible for root cause analysis because they have the detailed knowledge and context of their specific applications. They can quickly identify and address issues within their domain. The core philosophy of DevOps is “you build it, you run it, you own it,” which emphasizes the responsibility of DevOps teams for maintaining and troubleshooting their applications.
- Platform Teams are accountable for the overall stability and security of the underlying infrastructure. They provide the necessary tools, frameworks, and support to enable DevOps teams to perform their tasks effectively. While the DevOps teams handle the immediate response and root cause analysis for their applications, the Platform Team ensures that the infrastructure is secure, scalable, and reliable. They manage central components such as VPN Gateways and central Firewalls, and oversee the implementation of best practices across shared services.
This division of responsibilities ensures that each team can focus on their specific areas of expertise while maintaining overall system stability and performance.
Limitations
While this article provides a comprehensive guide to transitioning on-prem operations to a cloud-centric approach, it is important to acknowledge its limitations:
- The article does not cover every aspect of CCoE, DevOps, and SRE in detail.
- The recommendations are based on best practices and may need to be tailored to specific organizational contexts.
- A real-world case study is not included at this stage.
Conclusion
Adopting a Cloud Center of Excellence (CCoE), DevOps, and Site Reliability Engineering (SRE) practices can significantly enhance an organization’s ability to transition from on-prem operations to a cloud-centric approach. By following the outlined steps and applying the Prosci ADKAR model for change management, organizations can successfully navigate the transition process, motivate their teams, and achieve their digital transformation goals. Embracing a cloud-centric approach will enable organizations to stay competitive, drive innovation, and deliver value to their customers.

